基于CUDA的可扩展并行编程模型研究
摘 要 随着GPU处理能力和可编程性的不断提高,其应用也慢慢的从图形领域延伸到了需要强大计算能力的高性能计算领域。面对迅猛发展的多核以及GPU,传统的串行编程已经无法满足日益增长的计算能力。因此,不管是学术界还是工业界,都在寻找一个合适的并行编程模型来解决如何充分有效地利用GPU和CPU资源进行并行计算的难题。CUDA伴随着统一渲染架构的推出的一种通用的GPU编程模型,它绕过了图形流水线,直接对GPU的硬件核心做了一层多线程封装,根据其提供的多线程并行编程接口可以很有效地多线程编程,开发线程级并行性。
关键词 CUDA GPU 并行 编程模型
一、GPU通用计算的发展
虽然CPU在高性能计算领域一直以来都处于统治地位,然而随着GPU的逐渐强大,其拥有的强大的计算能力使其在高性能计算领域越来越有吸引力。虽然现在的处理器制作工艺越来越好,晶体管的大小越做越小,一个处理器核心上能放置的晶体管也越来越多。但是毕竟资源不是无限的,处理器核心上的晶体管在作为计算单元和控制单元之间只能做一个平衡。CPU选择了控制单元,其内部更多的晶体管用于设计控制器、分支预测单元、高速缓存Cache等非计算单元,真正用于计算的ALU只占晶体管的很小的一部分。这意味着CPU的每秒浮点操作(FLOPS)并不高,其主要考虑的还是能用性。GPU则不然,其设计之初就是为了图形处理,这需要大量的计算量。因此GPU的计算能力远超CPU,在计算密集型的高性能计算领域,GPU所扮演的角色也越来越重要.
GPU初期,是作为一种专门的图形处理器,所有的硬件结构都是固定功能单元。这一时期的GPU主要用于图形领域。由于硬件内部并没有可编程模块,因此程序员无法编程定制自己的功能函数。主要通过图形绘制接口OpenGL、DirectX来进行图形领域的绘制工作。随着GPU的顶点级和像素级的功能单元成为可编程模块,OpenGL和DirectX也做了相应的接口扩展支持程序员定制顶点着色器和像素着色器的功能。首先出现的是汇编级的着色器编写功能,程序员把GPU的汇编代码核函数放入一个字符串内。然后由相应的扩展接口读入代码并发编译成GPU硬件相应的指令,在运行时刻由OpenGL、DirectX相应的接口发射到GPU中执行。由于汇编代码可读性可编程性差,很快便出现了高级的着色器语言HLSL[1]、GLSL分别在DirectX和OpenGL上扩展了相应的编程接口。为了在DirectX和OpenGL上跨平台的编写着色语言,NVIDIA公司开发了cg语言[2]。cg可以在不同的GPU厂商、不同的操作系统平台下的DirectX和OpenGL都运行,从而解决了跨平台的GPU编程问题。与汇编级的着色器语言类似,这类高级的着色语言也是由扩展接口读入、编译并在运行时刻被发射到GPU执行,这种编译技术叫做即时编译技术(JIT)。至于编译和发射细节则由接口来封装,这对程序员来说是透明的,程序员只需要了解接口函数的调用规范。这一时期的编程语言特点是,都是作为一种着色语言流水线的绘制过程中完成自定义函数功能。这类GPU编程语言需要学习图形学流水线以及新的着色语言,学习曲线太高。虽然出现了很多能用计算的工作,但却并没让GPU在能用计算领域得到普及。
各种着色语言通用计算,由于程序员被强迫把他们的算法表达成图形流水线的概念,使得这类GPU编程语言的通用计算被限制于一些高级图形学开发者所使用。斯坦福大学图形学实验室为了更好的GPU通用化,开发了Brook[3]语言以及相应的编译器、运行时刻系统,把GPU作为一种协处理器用于通用计算。Brook是一种C语言扩展,是底层的图形硬件平台的一个抽象层。为程序员提供了一个流式的编程接口,掩藏了底层的图形流水线细节。并行的数据被声明为流,流的操作是通过程序员自定义的核函数,函数的参数为一些流的集合。函数的输入和输出是通过Brook提供的流的读写接口实现。程序员不再需要了解图形流水线,只需针对当前并行算法设计流以及核函数。AMD公司将Brook演化为商业版本Brook+用于其显卡的通用计算编程。
不管是HLSL还是Brook+都是与图形流水形相关的:HLSL本身就是遵循图形流水线来编程,而Brook则是利用图形流水线作为后端实现,编程复杂度和效率都受到了流水线的制约。随着统一渲染架构的出现,这是专门为GPU的通用化而设计的体系结构,GPU的通用计算也进入了一个新的层次。AMD公司的CTM[4]、NVIDIA公司的CUDA[5,6]都是随着统一架构而出现的GPU编程模型。前者是AMD为刚发布的面向高性能计算市场的一款流处理器Stream Processor服务,提供了一种汇编级的通用计算语言,利用Stream Processor的指令集直接编程。CTM自己的驱动在运行时刻直接发射代码,而非由图形流水线。这是一种非常直接的编程语言,其性能自然也比较高,只是这是一种汇编级的语言,可编程性不强,很难广泛的推广。
二、CUDA:可扩展并行编程模型
多核CPU和多核GPU的出现意味着并行系统已成为主流处理器芯片。此外,根据摩尔定律,其并行性将不断扩展。这带来了严峻的挑战,我们需要开发出可透明地扩展并行性的应用软件,以便利用日益增加的处理器内核数量,这种情况正如3D图形应用程序透明地扩展其并行性以支持配备各种数量的内核的多核GPU。
正如传统的事实那样,并行编程是一件很困难的事情。然而,如果你有一些早期CUDA扩展并行编程模型方面和对C语言程序的相关经验,那么,很多现有的经典程序都可以很容易的用并行来抽象。自从NVIDIA公司于2007年发布CUDA后,开发者已经很迅速的为很广泛的应用程序开发可扩展并行程序,这些程序包括医学计算、稀疏矩阵求解、排序、搜索、物理建模等等。这些程序对于大量的处理器内核和并发的线程来说扩展性是透明的。NVIDIA GPUs使用最新的Tesla统一图形计算体系结构,可以在笔记本,PC平台,还有工作站运行CUDA的C程序。而且,CUDA程序自适应于其它采用共享存储的并行体系结构,比如说,多核CPU。
CUDA的核心有三个重要抽象概念:线程组层次结构、共享存储器、屏蔽同步(barrier synchronization),它们为体系中的一个线程的常规C代码提供了一个清晰的并行结构。这些抽象提供了细粒度的数据并行化和线程并行化,嵌套于粗粒度的数据并行化和任务并行化之中。它们将指导程序员将问题分解为更小的片段,以便通过协作的方法并行解决。这样的分解透明性的扩展了大量的处理器核心:编译后的CUDA程序可以在任何数量的处理器内核上执行,只有运行时系统需要了解物理处理器数量。
CUDA是跟随着2006年12月NVIDIA公司的以G80为核心的统一渲染架构GeForce 8800显卡的面世而发布的,作为GPU高性能并行计算应用的并行编程模式和开发工具[5,6,7]。
2.1 G80体系结构
Telsa体系结构是建立在可伸缩的多线程SMs(流处理器)上的。当前的GPU实现了从768个线程到12,288个线程的并发执行。在广范围的并行上实现透明可扩展就是GPU体系与CUDA编程模型的目标。图A显示了一个含有14SMs的GPU---一个总共含有112个SP(streaming processor)核心---通过四个外部DRAM部分相互连接。当一个在主机CPU上的CUDA程序调用了一个核心栅格,CWDM(computer work distribution)单元便会遍历栅格中的所有线程块并把它们放到具有执行能力的SMs上去。一个线程块中所有线程会在一个SM上并发的执行。当线程块终止时,CWD单元又会在空缺的处理器上运行新的线程块。
每个SM包含有8个标量SP核,两个SFUs(特殊函数单元)来计算某些超越函数,一个MT IU(多线程指令发射单元),一个芯片共享存储。SM负责生成、管理,还有执行最高达768个并发线程,这些线程在硬件上,并且它们之间的调度代价为0。SM可以并发执行多达8个CUDA的线程块,受限于线程和内存资源。SM还实现了CUDA的通过一条指令__synchreads()栅栏来同步的内部机制。快速的栅栏同步,轻量级的线程生成和零代价的线程调度,高效的支持了细粒度的并行,支持一个新线程的生成来为每一个顶点,每一个像素和每一个数据点进行计算。
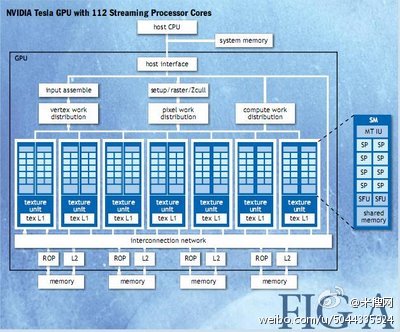
为了对在几个不同程序上运行的成千上万个线程进行管理,Tesla SM流处理器使用了一个新的体系,我们称之为SIMT(单指令多线程[8])。SM把SP上的每一个线程映射到SP核上, 每一个线程在它的指令地址和寄存器状态上独立的执行。SM的SIMT单元生成,管理调度以32个线程为一组的warp。一个SIMT指令被warp的所有线程同时执行。当某个warp阻塞时,零开销切换到另一个warp,所以warp是线程调度器的最小调度粒度。一个warp的所有32个线程者是执行的同一条指令路径,如果出现不同的分支,则每个分支都需要执行一遍,不执行某分支的线程执行空操作既可。因此应该尽量的让用一个warp的线程中不要有分支或者都执行同一分支,可以极大程度的提高CUDA的程序性能。每个SM会管理一个含有24个warp的线程池,每个warp有32个线程,总共含有768个线程。
2.2 CUDA编程模型
CUDA是C/C++编程语言的最小扩展。程序员写一个顺序执行的程序,这个程序可以是简单函数或大程序,我们称之为并行内核(kernel)。一个内核通过一系列的并行线程来实现并行。执行内核的线程(thread)被组织成线程块(block),而线程块又组成了栅格(grid)。线程块是可以一起协作的线程批(batch),它们通过一些快速的共享内存有效地共享数据,并同步执行以协调内存访问。更准确地说,用户可以在内核中指定同步点,线程块中的线程在到达此同步点时挂起。每个线程由线程ID标识,这是线程块中的线程号。为了帮助基于线程ID的复杂寻址,应用程序还可以将线程块指定为任意大小的一维、二维或三维线程阵列,并使用1个、2个或3个索引分量来标识每个线程。对于大小为 的一维线程块,索引为x的线程的线程ID为x;对于大小为( , )的二维线程块,索引为 的线程ID为 ;对于大小为 的三维线程块,索引为 的线程的线程ID为 。
线程块可以包含的最大线程数是有限制的(目前的最大值为512)。但是,执行相同内核的具有相同维度和大小的线程块可以组合到线程块栅格中,使单个内核调用中启动的线程总数变得更大。这是以线程协作的降低为代价的,因为同一栅格中不同线程块中的线程不能互相通信和同步。此模型允许内核有效运行,而不必在具有不同并行能力的各种设备上重新编译:如果设备只有非常小的并行能力,则可以顺序运行栅格的所有线程块,如果具有很大的并行能力,则可以并行运行栅格的所有线程块,通常是二者组合使用。每个线程块由其线程块ID标识,这是栅格中的线程块号。为了帮助基于线程块ID的复杂寻址,应用程序还可以将栅格指定为任意大小的一维或二维线程块栅格,并使用1个或2个索引分量来标识每个线程块。对于大小为 的一维线程块栅格,索引为x的线程块的线程块ID为x;对于大小为 的二维线程块栅格,索引为 的线程块的线程块ID为 。主机在执行对设备的内核调用时,线程组织为线程块并通过调度在各多处理器上执行。
作为一个非常简单的关于并行编程的例子,假设给定两个n维向量(浮点数)x和y,对于一个常量a,我们想要计算 的结果。这是BLAS(basic linear algebra subprograms)库中定义的一个叫做向量加乘的内核(kernel)函数。用串行处理器写的代码还有用CUDA来并行加速的代码可见图1。

global 声明该函数是个内核的入口点。这种函数在设备上执行,只能从主机中调用。CUDA程序通过扩展的函数调用语法kernel<>(…parameter list…);来执行并行内核。
dimGrid和dimBlock是类型为dim3的具有三个元素的向量,它们分别指定了栅格和线程块的维度信息。如果没有指定的话,那么默认值就为1。
在这个例子中,我们为一个向量的每一个元素指定了一个线程,并且指定一个线程块中有256个线程。每一个线程通过它的线程和线程块ID来计算元素的索引号,然后再对向量的某些元素执行相应的计算。串行和并行版本的这个例子是相似的。串行代码包含了一系列的循环,而这些循环之间是不相关的。这就意味着这种循环可以很机械地被转成并行内核:每一个循环的迭代过程变成一个与其它循环不相关的线程。通过为每一个输出元素指定一个线程,我们可以避免因为线程写内存需要同步时所出现的问题。
CUDA内核对于每一个线程来说就像是一个简单的C程序。所以,这比为向量操作写并行代码来得更直接,更简单。当执行一个内核时,程序中的并行是通过显式的对栅格维度和线程块维度进行设定来得到的。
CUDA程序中的并行执行和线程管理是自动的。所有线程的生成,调度和终止都由底层系统处理。实际上,一个Tesla体系的GPU会通过硬件对线程进行直接管理。一个线程块中的所有线程会并发的执行而且可能会因为内部函数__syncthreads()的调用而在某一个栅栏处同步。这种机制保证了没有一个线程会通过一个栅栏直到其它所有线程都到达这个栅栏的位置,从而有效的实现了同步。在所有线程都通过栅栏之后,这些线程就可以看到写内存的结果了,而这在线程通过栅栏之前是看不到的。所以,线程块中的线程可以通过同步栅栏的方式来实现互相交互的读写共享内存操作。
因为一个线程块中的线程可以共享局部内存,并可以通过栅栏来实现同步,这些线程就必须是在同一个物理处理器上或者多核处理器上。线程块的数量可以超过处理器的数量。这种虚拟化处理元素方式提供程序员自适应去决定哪一种编程粒度是最好的。这就给我们一个直觉:线程块的数目可以由将要处理的数据的大小来决定,而不是由所处系统的处理器数目来决定。这种特性也允许CUDA程序可以扩展至与不同的处理器数目相融合。
为了对元素的处理过程虚拟化以及提供可扩展性,CUDA要求线程块的执行必须是独立的。我们可以以任意的顺序来执行线程块,可以是并行的,也可以是串行的。不同的线程块之间没有直接的通信方法,但是,他们可以通过在全局内存上的原子操作来同步线程块之间的活动,使得全局内存上的变量对每个线程块是可见的,比如,可以原子的增加队列指针。
这种独立性要求允许线程块可以被任意数目的核心以任意的顺序被调度,这使得CUDA模型在任意数目的处理器上,任意的并行体系结构上是可扩展的。这种独立性还避免了线程块之间的死锁。
一个程序可以以独立的或非独立的方式来执行多个栅格。独立栅格的同步执行是需要有充足的硬件资源的。而非独立的栅格是顺序串行的执行,它们之间通过系统中隐式的栅栏来保证栅格执行之间的顺序执行(下一个栅格的执行在上一个栅格执行完成之前不会开始执行)。
线程在执行过程中可以从多个存储器中得到数据。每一个线程都含有一个私有的局部内存(local memory)。CUDA使用这部分内存作为线程私有的变量,而线程块中则含有对于线程块中所有线程都可见的共享内存(shared memory),共享内存中变量的生命周期与线程块块是一致的。所有的线程都可以访问同样的全局内存(global memory)。在共享内存与全局内存中使用shard和device类型来指定。在一个Tesla体系结构的GPU中,这些存储空间与不同的物理存储是相关的:每一个线程块有一个在芯片上的低延迟的共享内存,全局内存则是驻留在快速图形板的DRAM上。
共享内存可以认为是处理器上低延迟的内存,与L1 cache很相似。它可以为线程块中线程提供高性能的通信和数据共享。因为它与相关联的线程块具有相同的生命周期,所以内核代码一般是在会在共享存储变量上初始化数据,然后计算这些变量,最后把结果传回到全局内存空间上。顺序且独立的栅格中的线程块之间是通过全局内存来进行通信的,比如,读取输入和写结果。
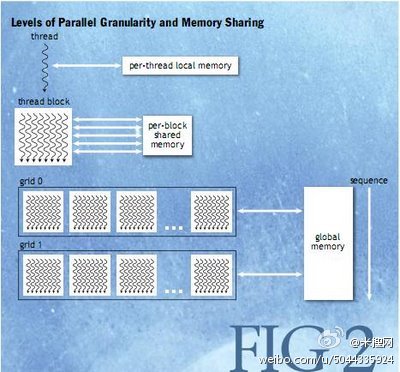
图2描述了嵌套的不同层次的线程:线程块,栅格线程,它还显示了不同层次的内存存储之间的联系:每个线程的局部内存,每个线程块的共享内存和每个程序的全局的数据内存存储。
一个程序使用CUDA运行时调用来管理对于内核可见的全局存储空间,比如,cudaMalloc()和cudaFree()。内核可能会在不同的设备上运行,就像是运行在GPU上运行内核一样。因此,应用程序必须使用cudaMemcpy()在已开辟空间与主机系统内存之间来复制数据。
CUDA编程模型与SPMD(single-program multiple data)在形式上是相似的—它明确的表达了并行性,而且每个内核是在确定数目的线程上运行的。然而,相比SPMD的大部分实现而言,CUDA编程表现得更具有自适应性,因为每个内核调用会动态的来为线程块指定确切数目的线程数目,为栅格指定确切数目的线程块数。程序员可以为内核使用一个更合适的并行度,而不是为程序执行的每个阶段指定相同数目的线程。
图3显示了一个类似SPMD的CUDA程序。它首先在实例化一个内核kernelF,该内核具有32块的2D栅格,每个2D线程块则包含有53个线程。然后它实例化内核kernelG,该内核具有4个块的1D栅格,每个块含有6个线程。由于内核kernelG依赖于kernelF的结果,所以它们会通过内部栅栏来实现同步。
线程块中的线程的并发性表明了细颗粒的数据和线程并行。一个栅格中的不同线程块之间则是表明了粗颗粒的数据和线程并行。而不同的栅格之间的并行则表明粗颗粒的任务并行。

2.3 CUDA的限制
但是,CUDA并不是说万能的通用计算器,它是有局限性的。当开发CUDA应用程序时,我们有必要理解CUDA模型在性能上的限制。线程与线程块的生成是通过执行内核来完成的,它们并不属于内核的一部分。由于线程块之间是互相独立的,这样就使得执行CUDA程序时的CUDA调度器只使用很小的运行时代价成为可能。实际上,Tesla体系已经实现了线程和线程块的硬件管理和调度。
任务并行度可以在线程块级别上来实现,但是块上的同步栅栏并不适合于在线程块的线程中执行任务并行。为了支持CUDA程序在任意数目的处理上运行,因此从属于相同栅格中的线程块之间的通信是不允许的 -- 它们必须独立的运行。因为CUDA要求线程块必须是独立的并且允许线程块可以以任意顺序来执行,因此,各线程块在把各自计算的结果综合起来之前,接下去要运行的那一个栅格是不可以执行的。然而,各线程块之间是可以通过在全局内存空间上的原子操作来实现同步操作的(比如,管理一个数据结构)。
递归函数调用在CUDA内核中是不允许的。在大部分的并行内核中实现递归是没有多少吸引力的,这是因为为成千上万的活动线程提供递归空间需要非常巨大的存储空间。对于使用递归的一般串行算法中,比如快速排序,用嵌套的数据并行来实现比明确的递归要好得多。
为了支持综合使用具有各其存储系统的CPU和GPU的体系结构,CUDA程序必须在主机存储和设备存储之间复制数据和结果。CPU和GPU之间的通信交互与数据传输代价已经通过DMA块传输引擎和快速交互方法达到最小化了。正因为如此,规模比较大的问题由于可以通过划分成小问题来解决,所以,规模比较大的问题会比规模小的问题的执行效率高。
2.4 CUDA程序实验
CUDA编程模型扩展了C语言,增加了一些并行的抽象。熟悉C语言的程序员可以很快地进行CUDA编程。
在CUDA介绍之后的一段很短时间,一些使用并行程序代码的程序现在都开始使用CUDA模型。比如,FHD-spiral MRI重建,动态分子法(molecular dynamics),天体物理学的n体问题模拟。在基于Tesla体系架构的GPUs上运行这些程序,比在串行CPUs上运行这些程序,速度得到很大的提升:MRI重建速度提高263倍;动态分子法可以提高10-100倍;n体问题模拟则可以得到50-250倍的提高。这些速度的提升是通过超高性能的在Tesla体系结构并行和超高的内存带宽来实现的。
三、并行编程的平民化
CUDA是一个并行编程的模型,它为程序员提供了简单的抽象以使程序员把精力都放在算法效率和开发可扩展的并行程序上。
CUDA是由NVIDIA GPUs在Tesla Unified graphics and computing architecture上的Geforce8 系列为当前的Quadro, Tesla, 还有未来的GPUs提供编程平台的。由CUDA提供了编程范例使开发者可以利用可扩展性并行处理器来对很多经典程序进行加速100倍以上。
CUDA抽象可以为多核CPU提供一个高效的编程环境。伊犁渃洲大学开发了一个源代码至源代码的原型转换框架,他们通过将一个并行的线程块映射到一个不断循环的物理线程的方式为多核CPU编译CUDA程序。用这种方式编译的CUDA内核会在可扩展性方面体现出优秀的性能[9]。
尽管CUDA还是一个比较新的产品,但是它已经成为大量开发任务目标 -- 现在有成千上万个CUDA程序开发者。超加速,直觉编程环境(表示很自然的编程),到处都可以编程的硬件,在这三者之间的结合在当前的市场中还很少见的情况下,CUDA不仅满足了这三点,而且还代表了一个平民化的并行编程模型。
四、总结及猜想
CUDA已经很好的实现了并行编程。借鉴CUDA的实现方式,从现在出现的并行编程模式来看,对于并行编程,主要的设计方向可以是如下三点:一,对目前串行化的命令型语言进行扩展。这种模式可以让程序员快速的掌握编程技巧,但是它也存在着串行语言的缺陷。CUDA就是这样的一种语言。二,通过添加编译器的指导语句来帮助编译器进行自动并行化。这种方式目前主要能够对循环进行并行化,由于受数据相关性以及编程的复杂性的制约,使其不可能成为主流的并行编程模型。典型的代表模型就是OpenMP。三,设计新的适用并行化的编程语言。
参 考 文 献(References)
- 1 GRAY K. Directx9 Programmable Graphics Pipeline[M]. Microsoft Press, 2003.
- 2 MARK W R, STEVEN R, KURT G, et al. Cg: A system for programming graphics hardware in a c-like language[J]. ACM Transactions on Graphics, 2003, 22:896–907.
- 3 BUCK I, FOLEY T, HORN D, et al. Brook for GPUs: stream computing on graphics hardware[J]. ACM Transactions on Graphics, 2004, 23(3):777–786.
- 4 NVIDIA. ATI CTM Guide[S]. 2006. http://www.nvidia.com/object/cuda%20develop.html.
- 5 NVIDIA. NVIDIA CUDA Compute Unified Device Architecture Programming Guide 2.0[S]. 2008. http://www.nvidia.com/object/cuda%20develop.html.
- 6 NVIDIA. NVIDIA CUDA Compute Unified Device Architecture Reference Manual 2.0[S]. 2008. http://www.nvidia.com/object/cuda%20develop.html.
- 7 NVIDIA. CUDA Technical Training Volume I:Introduction to CUDA Programming[S]. 2008. http://www.nvidia.com/object/cuda%20education.html.
- 8 Lindholm, E., Nickolls, J., Oberman, S., Montrym, J. 2008. NVIDIA Tesla: A unifed graphics and computing architecture. IEEE Micro 28(2).
- 9 Stratton, J.A., Stone, S. S., Hwu, W. W. 2008. M-CUDA: An effcient implementation of CUDA kernels on multicores. IMPACT Technical Report 08-01, University of Illinois at Urbana-Champaign, (February)
原文地址: http://knightliao.blogspot.jp/2009/04/scalable-parallel-programming-with-cuda.html